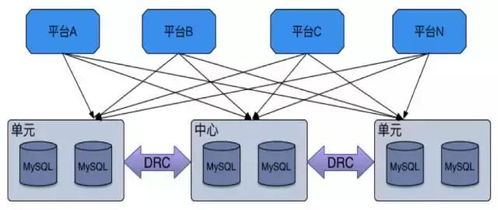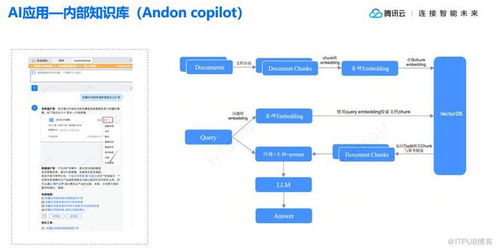
随着人工智能技术的快速发展,向量数据库与大模型的联合开发正成为推动数据库管理领域变革的关键力量。这种结合不仅显著降低了用户使用门槛,还催生了强大的飞轮效应,为数据处理和智能应用带来了前所未有的效率提升。
向量数据库通过高效存储和检索高维向量数据,为大模型提供了坚实的数据基础。传统关系型数据库在处理非结构化数据(如图像、文本、音频)时存在局限,而向量数据库专为此类场景设计,能够快速执行相似性搜索和近邻查询。这使得用户无需深入理解复杂的算法细节,即可轻松管理和查询海量非结构化数据。
与此大模型(如GPT系列、BERT等)凭借其强大的自然语言处理和推理能力,为用户提供了直观的交互界面。用户可以通过自然语言提问,大模型将查询转化为向量数据库可理解的搜索指令,并返回精准结果。这种无缝集成极大地简化了操作流程,用户无需掌握专业的查询语言(如SQL),即可高效访问数据库。
联合开发产生的飞轮效应体现在多个层面:数据量的增加提升了大模型的训练质量,而模型优化又进一步改善了向量数据库的查询精度和响应速度。随着更多用户加入,系统不断学习用户行为,优化数据索引和模型输出,形成良性循环。这不仅降低了新用户的学习成本,还加速了从数据到洞察的转化过程。
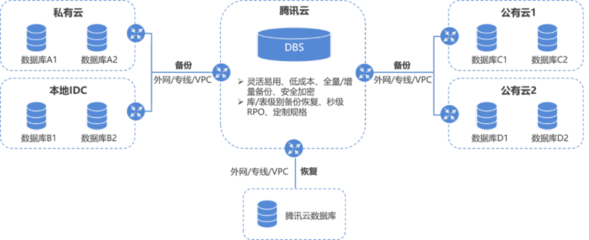
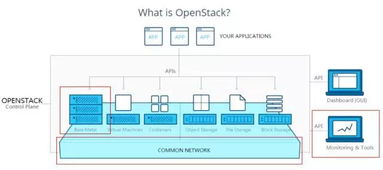
在数据库管理方面,这种联合方案推动了自动化与智能化的演进。例如,大模型可以自动生成数据清洗脚本、优化查询计划,甚至预测数据趋势,而向量数据库则确保这些操作的高效执行。企业因此能够以更低的资源投入,实现更精细的数据管理和更快的决策支持。
随着技术的成熟和生态的完善,向量数据库与大模型的深度融合将继续扩大其应用范围,从推荐系统、智能客服到科研分析,无处不在。用户使用门槛的降低不仅赋能了技术专家,更让普通业务人员能够直接利用高级数据工具,真正实现了数据民主化。
向量数据库与大模型的联合开发正通过飞轮效应重塑数据库管理的未来。它不仅是技术上的突破,更是用户体验的革新,为各行各业开启了智能数据应用的新篇章。